

< 일러스트 = 야구공작소 이동헌 >
# 서론 : 우리는 몇 개의 데이터를 만들어야 할까?
지난 칼럼에서 우리는 수비 동작 분석에 대하여 데이터를 쌓을 필요성을 이야기했다. 수비수의 관절 위치, 이동 궤적, 글러브를 뻗는 타이밍 같은 동작 정보. 그리고 “첫 스텝 방향이 적절했는가“, “송구 자세가 효율적이었는가” 같은 평가 라벨 등이 필요할 것이라고 언급했었다. 이 데이터는 게임로그나 트래킹 데이터와는 다르다. 자동으로 수집되지 않는다. 누군가 영상을 보고 판단하여 수많은 상황에 대해 라벨을 붙여주어야 한다.
이런 종류의 데이터를 대량으로 만들려면 어떻게 해야 할까? 한 경기당 우리는 54개의 아웃카운트를 잡고, KBO 기준으로는 720경기가 정규시즌에 열리니 정규시즌의 아웃카운트를 잡는 데이터는 39,000개에 육박한다. 이것을 10년동안 수집한다면 40만개에 육박하는 아웃카운트를 수집해야 하며 안타에 대해서도 분석하려면 더 많은 플레이 상황을 분석해야 할 것이다. 전문가 수십 명을 고용해서 이 수십만 개의 플레이에 대해 선수의 관절 위치, 이동 궤적, 동작 정보, 평가 라벨까지 모두 라벨을 붙이도록 할 수도 있겠지만 비용과 시간을 생각하면 쉽지 않다. 다른 방법을 생각해볼 수 있다. 이번 칼럼에서는 이러한 문제를 극복하기 위한 방법을 모색해본다.
# 비전문가와의 협업이 보여준 것
Tom Tango의 Fan Scouting Report는 참고할 만한 사례다. 2003년부터 2017년까지 운영된 이 프로젝트에서 Tango는 평가 프레임워크를 설계했고, 매년 수천 명의 팬이 실제 평가를 수행했다. 규칙은 엄격했다. 최소 10경기 이상 직접 관람한 팬만 평가할 수 있었고, 7개 항목을 5점 척도로 평가하되 어떤 통계도 참조하지 말고 오직 눈으로 본 것만 평가해야 했다.
결과는 의미 있었다. 팬 평가가 UZR과 높은 상관관계를 보였고, 특히 외야수 송구 능력의 경우 충분한 샘플이 쌓였을 때 0.78의 상관계수를 기록했다. 전문가가 기준을 세우고, 비전문가가 규모를 제공하는 구조가 작동한 사례다.
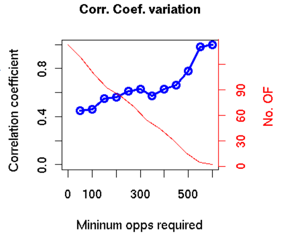
< FSR과 실제 기록간 상관관계. 더 많은 양의 데이터가 들어올수록 더 높은 상관관계를 보임을 알 수 있다. >
GameChanger도 비슷하다. 2009년 출시된 이 앱은 소프트웨어 전문가들이 플랫폼을 만들고, 부모와 코치들이 자발적으로 경기를 기록하는 구조로 운영됐다. 현재 1,300만 회 이상의 경기가 기록되어 있고, 2022년에는 NFHS(전미 고등학교 체육연맹)가 공식 파트너로 선정했다.
야구 바깥을 보면 더 큰 규모의 사례가 있다. ImageNet과 COCO 데이터셋은 물체의 위치 예측과 인간의 관절 예측에서 거대한 데이터셋을 크라우드소싱하여 만들어졌다. 이러한 데이터셋은 컴퓨터 비전 분야의 거대한 발전으로 이어졌다.

< COCO 데이터셋. 총 17개의 관절로 이루어진 여러명의 사람을 포함한 데이터셋이다. >
이 사례들에서 공통점을 찾을 수 있다. 전문가는 “무엇을 평가할 것인가“를 설계하고, 비전문가는 그 기준에 따라 대량의 판단을 수행한다. 기준이 명확하고 선택지가 단순할수록 비전문가의 참여가 쉬워지고, 데이터의 일관성도 높아진다. Fan Scouting Report의 7개 항목 5점 척도, ImageNet의 “이 사진에 X가 있는가“라는 이진 질문이 그런 구조였다.
# 수비 데이터셋과 크라우드소싱
앞서 설명한 Fan Scouting Report가 “눈으로 본 수비 인상“을 수집했다면, 우리가 이 데이터셋을 통해 이야기하고자 하는 건 “동작의 질에 대한 평가“다. 호크아이가 선수의 자세를 추적할 수 있지만, 낮은 프레임레이트로 인해 일부 신체 부위의 모션 블러 문제가 발생해 그 질에 문제가 생길 수 있다. 기존에 만들어놓은 인공지능 모델을 쓰더라도 이 한계는 변하지 않는다. 그리고 설령 인공지능 모델을 통해 관절의 위치를 정확히 찾을 수 있다 해도 그 자세가 효율적이었는지 아닌지는 여전히 사람의 판단이 필요할 것이다.
이 데이터셋을 만들기 위한 전문가와 비전문가의 협업 구조는 이렇게 될 수 있을 것이다. 전문가가 평가 기준을 설계한다. “좋은 첫 스텝이란 무엇인가“, “효율적인 송구 자세란 무엇인가“를 정의하고, 구체적인 체크리스트를 만든다. 비전문가는 영상을 보며 기준에 따라 라벨링한다. “이 플레이에서 첫 스텝 방향은 적절했는가?” 같은 질문에 예/아니오로 답하는 방식이다.
Fan Scouting Report가 7개 항목, 5점 척도로 평가를 구조화했듯이, 수비 동작 평가도 명확한 기준과 단순한 선택지로 구조화할 수 있을 것이다. 관절 위치 자체는 AI가 어느 정도 찾아줄 수 있으니, 사람은 그 위에서 “이 동작이 적절했는가“를 판단하는 역할을 맡게 된다.
물론 쉽지 않다. Fan Scouting Report는 “송구 능력이 좋아 보이는가“라는 직관적 질문이었지만, “첫 스텝의 타이밍이 적절했는가“는 훨씬 기술적인 판단이다. 평가 기준을 어떻게 설계하느냐에 따라 데이터의 품질이 달라질 것이다. 전문가의 역할이 그래서 중요하다.
품질 관리도 생각해야 한다. ImageNet은 같은 이미지를 여러 작업자에게 보여주고 다수결로 라벨을 확정했다. Fan Scouting Report는 충분한 샘플이 쌓여야 신뢰할 수 있다는 점을 명시했다. 수비 동작 평가도 비슷한 방식이 필요할 것이다. 가령 한 플레이를 여러 명이 평가하고, 일치도가 낮은 경우를 따로 검토하는 구조를 생각해볼 수 있다.
# 어쩌면 가능할지도 모른다
지난 칼럼이 수비 지표를 위한 데이터셋의 필요성에 대해 논했다면, 이번 칼럼에서는 그 데이터를 만들 수 있는 방법으로 전문가와 비전문가의 협력을 제시하였다. Fan Scouting Report가 14년간 보여줬고, ImageNet이 컴퓨터 비전에서 증명한 방식이다.
사실 이 방법만이 수비 데이터에 맥락을 반영할 유일한 방법은 아니다. 기존 OAA 모델에 강화학습을 적용하는 접근도 있을 수 있고, 호크아이 데이터를 더 정교하게 활용하는 방법도 있을 것이다. 평가 기준을 어떻게 설계할지, 품질을 어떻게 관리할지, 참여를 어떻게 유지할지 등, 제시한 방안에는 풀어야 할 문제가 많다. 그럼에도 불구하고 이전의 성공 사례들을 고려한다면 시도해볼만한 가치는 있지 않을까 한다.
야구공작소 표상훈 칼럼니스트
에디터 = 야구공작소 박두산, 장호재
일러스트 = 야구공작소 이동헌
ⓒ야구공작소. 출처 표기 없는 무단 전재 및 재배포를 금합니다. 상업적 사용은 별도 문의 바랍니다.





![[야구공작소 인포그래픽] “고우석 메이저리그 데뷔”
수많은 국내팬들이 원해왔던 그 순간이 찾아왔습니다. 고우석은 한국 시각으로 7월 6일, 미네소타 트윈스에 현금 트레이드로 이적했습니다
이번 이적을 통해 고우석은 메이저리그 계약을 맺을 예정이고 자연스럽게 빅리그 무대를 밟을 것입니다. 이는 진출 3년만의 이룬 성과입니다.
지난 2년 구속 저하 등의 이유로 마이너리그에서조차 부진했던 고우석. 하지만 그는 도전을 멈추지 않았습니다.
부진을 딪고 한걸음씩 나아가며 꿈을 이뤄낸 고우석의 앞으로의 활약을 응원합니다
제작: 야구공작소 이재성
(위 이미지는 AI를 활용해 제작되었습니다)
#고우석 #메이저리그 #MLB #미네소타 #트윈스](https://yagongso.com/wp-content/plugins/instagram-feed/img/placeholder.png)