

‘A 선수는 B 선수와 비슷하다’. 선수를 분석할 때 자주 나오는 이야기다. 체형 혹은 스윙 같은 스카우팅 관점에서도 가능하지만 선수의 성적 같은 정량적 데이터 측면에서도 이를 쓸 수 있다. 빌 제임스는 1980년대부터 선수 데이터를 사용해 선수를 비교했는데, 베이스볼 레퍼런스도 이 계산 방식을 참고해 Similarity Scores를 만들었다. 데이터를 이용해 닮은꼴의 선수를 찾는 도구로는 독보적이었다. 하지만 트래킹 데이터의 출현으로 인해 최근 새로운 도전자가 등장했다. 베이스볼 서번트의 Affinity가 그것이다.
두 방식 모두 데이터를 사용해 선수를 비교하는 것에 초점을 맞췄다. 그러나 완전히 다른 방식을 사용한다. 그렇다면 이 두 방식은 어떤 차이가 있을까? Similarity Scores와 Affinity가 무엇인지 알아보고 두 방식을 비교해보자.
베이스볼 레퍼런스 Similarity Scores
앞서 말했듯, 베이스볼 레퍼런스의 Similarity Scores는 1980년대 빌 제임스가 고안해낸 방식이다. 이후 베이스볼 레퍼런스에서 그의 책인 ‘The Politics of Glory’에서 계산 방법을 가져와 지금의 Similarity Scores를 만들었다.
기본 뼈대는 이렇다. 우선 1,000점으로 시작한다. 그리고 한 선수와 비교할 선수들의 기록을 보고 차이가 나는 기록들을 뺀다.
타자
타자는 아래의 기록이 차이가 날 때마다 1점씩 삭감된다.
- 20경기 차이마다 1점 삭감
- 75타수 차이마다 1점 삭감
- 10득점 차이마다 1점 삭감
- 15안타 차이마다 1점 삭감
- 2루타 5개 차이마다 1점 삭감
- 3루타 4개 차이마다 1점 삭감
- 홈런 2개 차이마다 1점 삭감
- 타점 10개 차이마다 1점 삭감
- 볼넷 25개 차이마다 1점 삭감
- 삼진 150개 차이마다 1점 삭감
- 도루 20개 차이마다 1점 삭감
- 타율 1리 차이마다 1점 삭감
- 장타율 0.002 차이마다 1점 삭감
타자는 수비 포지션에도 차이가 있기 때문에 각 포지션마다 차이점을 뒀다. 각각의 포지션마다 값이 있고 비교하는 두 선수의 포지션 차이를 뺀다. 각 포지션 별 값은 아래와 같다. 예를 들어 3루수인 A 선수와 닮은 선수를 찾을 때 1루수 B 선수는 84 – 12 = 72점의 감점을 받는다.
- 포수 240점
- 유격수 168점
- 2루수 132점
- 3루수 84점
- 외야수 48점
- 1루수 12점
- 지명타자 0점
여기서 베이스볼 레퍼런스와 빌 제임스의 계산 방식에 차이점이 있다. 빌 제임스의 경우 선수의 주 포지션만 사용했다. 그러나 베이스볼 레퍼런스는 주 포지션이 여럿 있는 선수의 경우 포지션 점수의 평균을 이용해 점수를 매겼다.
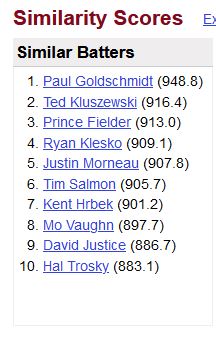
프레디 프리먼의 Similarity Scores
위는 프레디 프리먼의 Similarity Scores다. 900점대 안팎이면 꽤 비슷한 선수라고 볼 수 있다. 앞서 언급했듯이 Similarity Scores는 포지션별로 점수가 있기 때문에 상위권에 위치한 선수들이 다 프리먼과 같은 1루수 출신이다.
투수
투수의 경우 아래와 같다.
- 1승 차이마다 1점 삭감
- 2패 차이마다 1점 삭감
- 0.002 승률 차이마다 1점 삭감 (최대 100점)
- 0.02 평균자책점 차이마다 1점 삭감 (최대 100점)
- 등판 10경기 차이마다 1점 삭감
- 선발 등판 20경기 차이마다 1점 삭감
- 완투 20경기 차이마다 1점 삭감
- 50이닝 차이마다 1점 삭감
- 피안타 50개 차이마다 1점 삭감
- 탈삼진 30개 차이마다 1점 삭감
- 볼넷 허용 10개 차이마다 1점 삭감
- 완봉 5경기 차이마다 1점 삭감
- 세이브 3개 차이마다 1점 삭감
투수는 타자와 다르게 포지션이 세분화 되어있지 않다. 하지만 점수 삭감에서 세부적인 부분이 추가로 존재해 복잡하다. 우선 던지는 손, 선발 혹은 계투에 따른 차이점이 있다. 같은 선발이지만 던지는 손이 다를 경우 10점이 삭감된다. 계투일 경우엔 25점이 삭감된다.
계투의 경우 승률 차이에 따른 점수 삭감은 1점이 아닌 0.5점이다. 여기서 계투란 선발보다 계투로서 출전이 많으며 평균 4이닝 이하를 던진 투수를 말한다. 그리고 승률 차이에 따른 점수 삭감은 승패 차이에 따른 삭감의 1.5배를 넘을 수 없다. 예를 들어 승 혹은 패 차이에서 100점이 삭감됐다면, 승률에서는 150점 이상 삭감될 수 없다는 뜻이다.
레퍼런스는 각 선수 페이지마다 Similarity Scores를 표시하고 있는데, 이에 포함되려면 최소 100이닝을 던지거나 500타수를 기록해야 한다.
이렇듯 베이스볼 레퍼런스에 계산식이 있지만 직관적이지 않다. 앞서 말한 점수들이 왜 삭감되야 하고 왜 차이점을 두는지에 대한 자세한 설명이 없다.
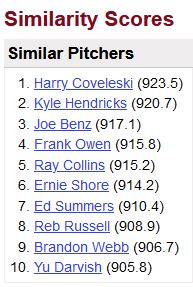
제이콥 디그롬의 Similarity Scores
위의 표를 보면서 의아하다고 생각한 사람이 꽤 있을 것이다. 카일 헨드릭스와 브랜든 웹은 디그롬과 전혀 다른 유형의 선수다. 근데 왜 900점이 넘는 높은 점수를 받았을까? 이유는 다양하겠지만 한 가지를 꼽자면 디그롬의 적은 승수가 아무래도 영향을 끼쳤을 것이다. 디그롬은 8년간 77승 53패를 기록했다. 핸드릭스 또한 8년의 커리어에서 83승 55패를 기록했다. 승수로만 따졌을 때 두 선수는 큰 차이점을 보이지 않았다.
타자의 경우 포지션별로 유형이 다르다. 또한 기록으로 선수의 성향을 파악할 수 있다. 투수도 기록을 보고 어느 정도 성향을 파악 할 수 있다. 그러나 Similarity Scores에는 구속과 무브먼트 같은, 투수를 비교할 때 가장 중요한 부분이 없기에 아쉬운 부분이 있다.
베이스볼 서번트 Affinity
바로 이런 점을 보완할 수 있는 게 베이스볼 서번트의 Affinity다. Affinity를 직역하면 친연성 혹은 관련성이다. 앞의 Similarity Scores가 성적 등 여러 수치를 기반으로 계산되지만, 들어가는 변수들이 너무 많고 왜 그렇게 가중치가 주어지는지도 직관적이지 못하다.
반면 Affinity는 트래킹 데이터를 사용하기 때문에 직관적이다. 투수의 경우 구속과 무브먼트를 사용해 비교한다. 타자의 경우 발사각과 타구 속도를 사용한다. 또한, 베이스볼 서번트의 그래픽은 어떤 선수가 누구와 닮은꼴인지, 왜 그런지 한눈에 알아보게 도와준다.
투수
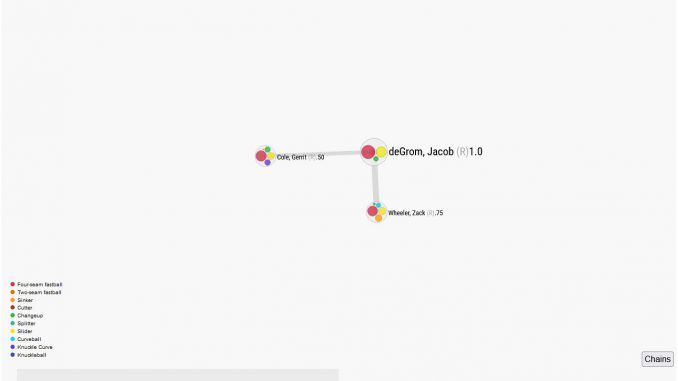
제이콥 디그롬의 Affinity (speed and movement)
위의 그래프를 보면 디그롬과 비슷한 유형의 투수들이 클러스터 형식으로 나타난다. 우선 원 안에 있는 가지각색의 작은 원들은 구종을 뜻한다. 원의 크기는 빈도수를 뜻한다. 선수 이름 옆에 보이는 숫자는 매치 스코어다. 매치 스코어는 선수의 구속, 구종 그리고 무브먼트를 계산해서 나타난다. 1과 가까울수록 비교하는 선수와 비슷하다.
2021년 디그롬과 가장 닮은꼴인 선수는 매치 스코어 0.75의 잭 휠러다. 구종 부분에서는 빨간 원인 포심 패스트볼과 노란 원인 슬라이더의 빈도수가 비슷한 것을 확인할 수 있다. 게릿 콜의 경우 평균 구속은 디그롬과 비슷할 수 있으나 슬라이더 빈도수에서 차이가 난다.
타자

타구 유형
타자의 경우 히팅 프로필을 사용한다. 히팅 프로필은 타자의 발사각과 타구 속도를 기반해 설정됐다. 위에 보이는 사진의 왼쪽 하단을 보면 타구를 6개의 유형으로 분리해 시각화했다. 히팅 프로필은 투수의 구속/무브먼트 차트와는 다르게 볼넷과 삼진 또한 기록하고 있다.
제일 하단의 볼넷과 삼진을 제외한 6개의 유형 중 위의 3개가 안타를 만들어낼 확률이 높은 타구다. 그리고 아래 3개는 공의 밑 부분, 윗부분을 친 타구, 그리고 약한 타구다.
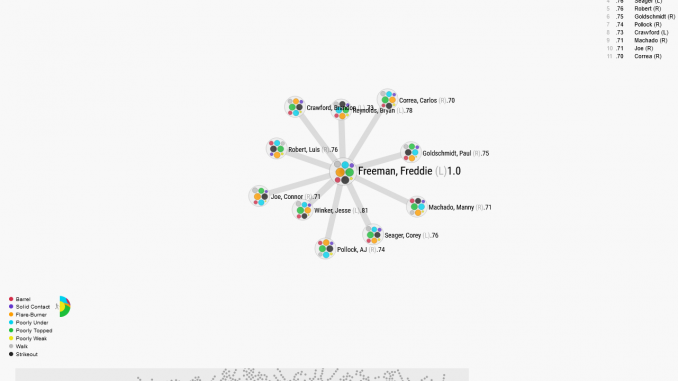
2021년 프레디 프리먼의 Affinity (Hitting Profile)
프리먼의 히팅 차트를 보면 비슷한 선수로 제시 윙커, 브라이언 레이놀즈, 폴 골드슈미트가 보인다. 위의 그래프에서 보이는 선수들 모두 매칭 포인트가 0.70을 넘는 선수다. 타자의 타구, 볼넷, 삼진을 계산해 비교함으로써 온전히 타격에서의 비교를 할 수가 있었다. 그러나 히팅 프로필 또한 최근 한 시즌만 확인할 수 있다. 그리고 포지션별로 분배를 할 수 없다는 점이 아쉽다. 프리먼의 경우 골드슈미트가 두 컴패리즌에서 모두 나왔다. 그러나 프리먼은 좌타자, 골드슈미트는 우타자인 점을 봤을 때, 완벽히 닮은꼴이라고 하기엔 무리가 있다.
컴패리즌을 컴패리즌하기
이렇게 두 가지의 컴패리즌을 알아봤다. 두 개 모두 선수를 데이터로 비교한다는 점에서 메리트가 있다. 그러나 각기 다른 형식의 데이터를 사용하므로 차이점이 분명히 존재한다.
Similarity Scores의 경우 방대한 데이터를 사용해 야구 초창기의 선수들과 현재의 선수들을 비교할 수가 있다. 또한 타자의 경우 포지션별로 차이를 뒀다. 이 차이로 인해 비교되는 선수들이 대부분 동 포지션 선수였다. 하지만 투수 비교에서는 물음표가 붙었다. 성적의 결과값을 주로 사용하기에 투수의 유형이 완전히 다른 선수들이 높은 점수를 받기도 했다. 또한, 점수를 계산하는 과정이 직관적이지 못하고 어렵게 느껴진다.
Affinity는 Similarity Scores와 비교했을 때 훨씬 직관적이다. 또한 투수의 경우 선수의 유형을 더 자세하게 알 수 있다. 타자는 타구 데이터를 기반으로 비교를 한다. 온전히 타자의 프로필만 비교함으로써 같은 유형의 ‘타자’를 찾을 수 있다. 그러나 포지션별로 나누지 않기에 비슷한 ‘야수’는 찾기 어렵다. 제일 큰 문제점은 데이터의 표본에 있다. 최근 시즌의 데이터만 확인할 수 있고 데이터가 없는 예전 선수의 기록과는 비교를 할 수 없다는 불편한 점이 있다.
이 글은 더 나은 컴패리즌 방식을 찾는 글이 아니다. 두 개의 다른 컴패리즌 방식을 비교해 알맞게 사용하는 방법을 찾는 글이다. 야수의 커리어 전반적인 컴패리즌을 찾고 싶다면 Similarity Scores를 사용해 예전 선수들까지 비교를 할 수 있다. 투수의 유형이 궁금하다면 Affinity를 사용해 어떤 공을 던지며 비슷한 유형의 선수가 이번 시즌에 누가 있는지 찾을 수 있다. 이렇듯 각 컴패리즌 방식의 강점을 잘 활용하는 게 관건이다.
참고 = Baseball-Reference, Baseball Savant
야구공작소 권승환 칼럼니스트
에디터 = 야구공작소 홍기훈
ⓒ야구공작소. 출처 표기 없는 무단 전재 및 재배포를 금합니다. 상업적 사용은 별도 문의 바랍니다.





![[야구공작소 인포그래픽] “고우석 메이저리그 데뷔”
수많은 국내팬들이 원해왔던 그 순간이 찾아왔습니다. 고우석은 한국 시각으로 7월 6일, 미네소타 트윈스에 현금 트레이드로 이적했습니다
이번 이적을 통해 고우석은 메이저리그 계약을 맺을 예정이고 자연스럽게 빅리그 무대를 밟을 것입니다. 이는 진출 3년만의 이룬 성과입니다.
지난 2년 구속 저하 등의 이유로 마이너리그에서조차 부진했던 고우석. 하지만 그는 도전을 멈추지 않았습니다.
부진을 딪고 한걸음씩 나아가며 꿈을 이뤄낸 고우석의 앞으로의 활약을 응원합니다
제작: 야구공작소 이재성
(위 이미지는 AI를 활용해 제작되었습니다)
#고우석 #메이저리그 #MLB #미네소타 #트윈스](https://yagongso.com/wp-content/plugins/instagram-feed/img/placeholder.png)